Richard Feynman was the most awesome person ever. He essentially was an upgraded version of Einstein, at least when it comes to human features. His personality is much more accessible to ordinary people: he’s the subject of anecdotes featuring bongo drums, nuclear secrets and lock picking. He was somewhat a ladies’ man, he frequented strip clubs. He was curious of how things worked and eager to teach what he found out about them — something I think is the most admirable quality in a person.
Most people could learn something important from Feynman. People should maintain their natural curiosity through their lives. People should try to find things that are interesting to them, and them actively find out what makes them tick. To me, “I don’t know” is a very weird answer when practically everyone in the developed world has access to the Internet.
Most people seem to think finding out about things and knowing about things is something you can’t do — unless you get a monthly salary of it. Or, that knowledge is for the elite. Or, that knowledge is inherently dangerous and against their values. They should realize there indeed is a good salary for someone who upkeeps and uses the ignorance.
People are afraid of knowledge because of they don’t want to be a part of the elite. People think of Albert Einstein when they think of a genius, they should be thinking of Richard Feynman. Einstein was eccentric, Feynman was cool. Richard Feynman knew about things but still went to strip clubs, broke into offices for fun and I would think generally enjoyed his life.
So, next time, refer to someone as a regular Feynman — sarcastically or not — when you refer to a genius.
I just stumbled upon the Google Chart API and I couldn’t resist playing with it (statistics being a fetish of mine). A few moments later, I came up with some PHP code that uses my stats plugin for WordPress to fetch page views and generates an URL for the Google API (see below for the attached source code).
The main idea behind Google Chart is that the chart is an image and all data for the chart is in the URL. That includes the chart title, size and the data sets. Personally, I think this is a brilliant idea. You can embed the charts anywhere you can use images and best of all, you don’t need to have data anywhere else but in the URL (you don’t even need to duplicate the generated image in your own webspace).
You can also pretty much generate charts by hand if needed.
On the other hand, when using dynamic data fetched from a database, it is a relatively small task to encode the data into the format Google Chart uses. They even provide a Javascript snippet for that (obviously, you might want to do that server-side – see below). Or, you can simply use floating point numbers if you don’t mind long URLs (and I’m not even sure you can always use very long URLs).
For example, below there’s a graph generated from daily visits to this site:
And here is the URL used to get that graph (lines split for convenience):
The above URL has quite Google-like short parameter names but that’s obviously because of technical limitations. The chd parameter is where the data set for the graph is: s:NQGHJ – simple encoding :encoded data.
One interesting aspect arises because of the encoding: you need to fit your data set to use the granularity the encoding has. E.g. when using simple encoding and encoding a data set of 0, 4.7 and 244, you have to normalize and remap the data so the data goes from 0 (character A) to 61 (character 9), not from 0 to 244. That may sound horribly inaccurate but remember, nobody measures the charts with a ruler – they look at the numbers for accurate data. And there are more accurate encodings.
I like how the charts look slick. A lot of existing libraries and APIs for similar stuff tend to have less aesthetic appeal. Anti-aliasing does not better stats make but it certainly looks more professional. The API also has nice features such as adding arrows and red X’es on a graph (think an arrow with the caption “stock market crash” – after which the graph plummets), the always useful Venn diagrams (see right) and other usual stuff you’d need.
Anyway, my original point was that Chart is a cool API, is probably easier to use and faster to install than gnuplot or other chart drawing software, is compatible with any browser able to display images and it’s free for everyone to use (the limit is something like 50 thousand views per user per day – and I guess their policy says nothing against caching the charts on your own site). Check it out.
P.S. This is quite obvious but… I predict that in the future, Google will use the accumulated charts for some kind of statistics search. The charts contain text (label, title) so a Google search result might include relevantly labeled graphs. Which is an interesting scenario, considering the Internet is full of lies, kooks and gullible users.
google_chart.zip the bit of code I used to visualize page views (it’s supposed to be run under a WordPress page and it needs my stats plugin)
Here is yet another list of free games considered awesome by the majority of this blog’s writers (me). As you can see, my taste in games is quite retro.
Cave Story (D?kutsu monogatari, ????)
Note: The author of Cave Story has requested people to stop distributing the game, this is because is is to be expected to be available on WiiWare (I hope the game will not be exclusive to Wii gamers). Here’s one such rumor.
Try if you like: Megaman 2, Metroid – any good NES game that defined your childhood
Here is a game that is on every free games list and for a reason. Cave Story feels and looks like a NES game that was updated for a SNES release. The graphics are simple and sometimes blocky – but intentionally so. Similarly, the music is something you would hear in a NES game. In a good NES game. I still find myself humming the catchy tunes even though I finished the game a while ago.
The basic game is about making a little guy run, jump and shoot. There are a variety of weapons, some weapon choices even alter the game story. There even is simple leveling up, some enemies drop crystals that make your current weapon more powerful.
Best of all, there clearly has been huge effort in making the game more than a retro run-and-gun game. There actually is a good, long story about cute creatures that need your help. The levels are huge and varied: there even is a side-scrolling level. Another level twists the standard game mechanics as you need to negotiate a flooded area with vortices that usually pull you into unsurprisingly lethal spikes.
There also are memorable boss fights including one with a boss larger than the screen. Now that I mentioned it, the game is simply memorable. There are too many things to tell about this game. Too bad the game is free because it clearly is worth money.
The game is available at least for PC, Mac and GP2X.
Cave Story Deluxe Pack (you’ll want to download this – includes an English translation and the awesome soundtrack)
Try if you like: SimCity and other building games, trains in general
Transport Tycoon probably is the game that I have spent the most time with, ever. It’s basically about tiny trains hauling things from A to B, then hauling things from B to C.
Sounds boring. Why is it so awesome?
Because there is a ton of things to try to make your transport empire make more money. You could build a simple track from place A to B and then another track from C to D. But if you’re smart, you’ll build a whole railway system and connect satellite stations to it – just like it is done in the real world. Then, to make trains smarter, you’ll add signals, build more efficient stations and update your old routes to monorails and so on.
I think the defining factor that makes OpenTTD so fun is that it is actually you who builds all these things. For example, in some other simple game you could select between a few station types – each with their own cost and efficiency. In OpenTTD, you have exactly one station type. What makes a station efficient is how you connect the rails to it, how many platforms it has and do slower trains clog up the whole system. To give some perspective, here is the game manual on stations.
There also are airplanes, ships and trucks but they’re rubbish.
OpenTTD is ported on many systems as it is open source. There even is a Nintendo DS port.
Star Control 2 is probably one of the most loved games from the early 1990s. It combines exactly right amounts of adventure, action, exploration and humor. The game is about you, the spaceship captain, trying to free Earth and the known universe from the Ur-Quan (tentacled slavemasters).
The gameplay consists of a top-down view of your ship. The ship is controlled by rotating and thrusting – nothing new since Spacewar or Asteroids. The controls remain the same whether the ship was in hyperspace, traveling for hundreds of light years, and during close encounters with enemies, i.e. dogfighting to death while orbiting a planet.
When your ship is in hyperspace, you can travel between stars. Every star has planets orbiting it, most of the game features you launching an exploratory ship down on the planets and collecting minerals and biological samples. The things you find act as money: at Earth you can trade minerals and other stuff to fuel, technology, crew and fighters. The biological samples can be traded for new technology when you come across a certain alien race.
Some stars are the homeworlds of alien races – some friendly, some less friendly. When meeting an alien, you will converse with them using different bits of dialogue, similarly to most adventure games in general. You will often get information where to find more alien races and sometimes you’ll get a quest to complete. Sometimes, you’ll be able to avoid battles if you are smart when conversing with the aliens. It is during these encounters you will get the most laughs.
The presentation is nothing short of awesome. Every race you meet has its own theme music, animated graphics, voice acting and even font for the captions.
Considering the climate change hasn’t eliminated winter yet, here’s something to keep your head warm. As a bonus, it won’t deduct from your carefully planned geek look.
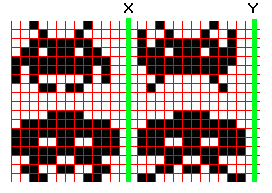
The hat inside out, note the two threads running around the hat
The pattern repeats three times around the hat (the hat is 96 stitches around which fits nicely to my adult-sized head). You can use more colors but this results in more threads running inside the hat (and probably is a bit harder to knit), maybe you could use this to your advantage and make the hat warmer.
Note that the above pattern is 28 stitches wide. If your hat isn’t e.g. 28*3=84 stitches wide, you have to pad the pattern with empty stitches. Add the padding stitches at the green lines, in my case there are two and two padding stitches added (i.e. there are four empty stitches between the bottom sprite) to make the pattern 32 stitches wide making the pattern fit exactly three times on the hat. Also, keep in mind the hat starts to get narrower after the pattern ends, so you can’t use the same pattern all the way to the top. In this case only two rows of sprites could be fit on the hat (I wanted a hat that isn’t floppy on the top).
Wikipedia has a pretty comprehensive article on knitting (take a look at the instructional links) but you’ll probably get the same information in a much nicer form if you ask your mom or grandmother. In any case, knitting is not hard. You just have to have some finger dexterity which most geeks have, because geeks type fast.
Most websites feature the possibility to rate articles, files, videos and other content. It’s a good way to keep popular content the most visible. If the ratings are to be used seriously, we need accurate data. Most rating systems do not necessarily provide accurate data.
The biggest reason why rating content doesn’t work as well as it could is the fact humans use the system. Humans are very noisy when it comes to input. While the law of large numbers eventually ensures consensus, choosing a good rating system could make rating stable much faster.
Pick a number
Probably the most common way to rate content is to give it a score, usually between one and five. Some sites use a larger scale, notably IMDB, which scores movies between one and ten points. Now, here’s the big revelation: this is not a very good way to do this.
The more options you have, the harder it is to choose accurately. IMDB probably has an user base of hundreds of thousands (most movies have tens of thousands of voters), which means they could simply have two ratings: “I liked this movie” and “I didn’t like this movie”. Maybe they could throw in “I didn’t like this but I don’t hate it either”, too. Considering the huge amount of votes, they still would get an average score that provided enough accuracy for their charts and whatnot.
Another downside in such a system is the fact people give biased scores. The reasons might vary, my personal excuse is that school grades in Finland go traditionally from four to ten, roughly representing a score of 40 % to 100 % respectively. This means, I rarely vote outside the familiar scale, unless a movie has to be punished and given the lowest rating possible. Which is another example of the noisy input people provide.
Pros: Easy to get accurate data from small user base Cons: Very noisy, hard to decide between similar options
Thumbs
A slightly more modern way to rate things is ironically a very old method: thumbing things up or down, much like a Roman emperor. As stated above, the limited scale still provides accurate ratings thanks to the law of large numbers. Giving the user two options removes the statistical noise (excluding accidental votes), it is easier to extract the information by asking simply “Did you like this or not?”.
However, giving the user less options limits his or her ability to rank items on their personal lists and favorites, if that is needed. This could be solved with additional questions such as “Did you like X more than Y?”, or simply allowing the user to order items from best to worst in a list. In addition, an ordered list based approach would obviously give more perspective for the user if he or she wants to provide accurate input, having to constantly think of an item really is better than the item below it.
Pros: Easy to vote, less noise Cons: Needs a bigger data set to provide accurate data
Obviously, all the above is to taken seriously only if you really want to either get better input or if you want to avoid a bit of work: a fancy system doesn’t necessarily provide that much and could only be confusing to the users. My personal choice would be a minimalistic approach, thumbing up or down, that is. Any comments?
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
 Richard Feynman was the most awesome person ever. He essentially was an upgraded version of Einstein, at least when it comes to human features. His personality is much more accessible to ordinary people: he’s the subject of anecdotes featuring bongo drums, nuclear secrets and lock picking. He was somewhat a ladies’ man, he frequented strip clubs. He was curious of how things worked and eager to teach what he found out about them — something I think is the most admirable quality in a person.
Richard Feynman was the most awesome person ever. He essentially was an upgraded version of Einstein, at least when it comes to human features. His personality is much more accessible to ordinary people: he’s the subject of anecdotes featuring bongo drums, nuclear secrets and lock picking. He was somewhat a ladies’ man, he frequented strip clubs. He was curious of how things worked and eager to teach what he found out about them — something I think is the most admirable quality in a person. Most people could learn something important from Feynman. People should maintain their natural curiosity through their lives. People should try to find things that are interesting to them, and them actively find out what makes them tick. To me, “I don’t know” is a very weird answer when practically everyone in the developed world has access to the Internet.
Most people could learn something important from Feynman. People should maintain their natural curiosity through their lives. People should try to find things that are interesting to them, and them actively find out what makes them tick. To me, “I don’t know” is a very weird answer when practically everyone in the developed world has access to the Internet. I like how the charts look slick. A lot of existing libraries and APIs for similar stuff tend to have less aesthetic appeal. Anti-aliasing does not better stats make but it certainly looks more professional. The API also has nice features such as adding arrows and red X’es on a graph (think an arrow with the caption “stock market crash” – after which the graph plummets), the always useful
I like how the charts look slick. A lot of existing libraries and APIs for similar stuff tend to have less aesthetic appeal. Anti-aliasing does not better stats make but it certainly looks more professional. The API also has nice features such as adding arrows and red X’es on a graph (think an arrow with the caption “stock market crash” – after which the graph plummets), the always useful  There also are memorable boss fights including one with a boss larger than the screen. Now that I mentioned it, the game is simply memorable. There are too many things to tell about this game. Too bad the game is free because it clearly is worth money.
There also are memorable boss fights including one with a boss larger than the screen. Now that I mentioned it, the game is simply memorable. There are too many things to tell about this game. Too bad the game is free because it clearly is worth money.